
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- JS
- 씨홀스
- 엘든링
- 뱀파이어서바이벌
- 취미
- guide
- ubuntu
- 공략
- 게임
- 여행
- JavaScript
- 세부
- 다이빙
- 개발툴
- intellij
- docker
- 야생의숨결
- window11
- 안드로이드
- Front-end
- window
- PostgreSQL
- 스쿠버다이빙
- poe2
- Linux
- window10
- 오픈워터
- WebView
- 젤다의전설
- 어드벤스
- Today
- Total
Rianshin
v-for과 key, 그리고 성능사이의 관계 본문
v-for을 사용하다보면 생각보다 요놈이 문제 많은 녀석이라는걸 느낄 때가 있다.
그런데 국내나 해외나 이 v-for에 대해서 제대로 적어놓은 녀석이 별로 없는거 같다.
그냥 불편해도 사용하는건지...
사용시 주의를 요하는 녀석인데 그 이유에 대해서 논해보도록 하자.

코딩을 하다보면 v-for은 안쓸래야 안쓸 수가 없다.
굉장히 좋은녀석이지만 몇가지 문제점이 존재한다.
일단. v-for은 해당 데이터의 길이가 0이면 그리지 않는다.
그래서 굳이 v-if를 달 필요가 없다는건 장점이다.
하지만 문제는 길이가 가변할 경우이다.
대부분 v-for의 문제는 가변하는 길이에서 오는 것이다.
v-for에서 데이터를 처리하는 방식은 아래와 같다.(완벽하게 같지는 않고 얼추 맞음)
1. data의 길이가 0(혹은 초기화)에서 n의 길이가 되었을 경우 n개의 컴포넌트를 만들고 dom으로 바꾼다.
2. 1번 이후 당연히 컴포넌트는 새로 만들어졌으므로(dom으로 인스턴스화 됬으므로) created와 mounted 이벤트가 발생
3. data의 길이가 n개에서 m개로 증가 되었다.(m은 n보다 크다)
4. 3번 이후 컴포넌트가 추가되었지만 기존의 dom자체를 파기하지는 않고 적절히 순서를 유지한다.(새 데이터가 앞일지 뒤일지 중간일지 모르므로)
5. 데이터가 당연히 추가되야하므로 m-n개 만큼 추가로 dom을 생성한다 당연히 추가로 생성된 컴포넌트는 created와 mounted가 발생한다.
여기서 눈여겨 볼것은 데이터가 추가되었을 때 기존의 dom을 파기하지 않는다는것, 이말은 기존의 컴포넌트를 파기하지 않는다는 말과 동의어다.
그렇기 때문에 데이터가 늘어나서 추가로 돔이 생겨도 기존의 dom이 파기되지는 않았으므로 이벤트는 발생하지 않는다.
싹 재 렌더링을 하지 않기 때문에 당연히 성능이 상승하게 된다.
여기서 문제점이 발생하는 경우가 많다.
이 때 발생하는 문제점
일단 이 문제점 보다 이번에는 key에 초점을 맞춰보도록 하자.
이 때까지 위의 이야기는 다 key의 역활을 말하기 위해서 한것이다.
4번에 dom자체를 파기하지 않고 적절한 순서를 유지하는것은 바로 key때문에 가능하다.
데이터가 다시 업데이트 될 때 가상돔과 돔의 key를 비교한다.
key가 지정되어있다면 이 key를 통해서 특정 녀석을 "재 렌더링 할지"정하게 된다.
key가 없다고 반드시 재 랜더링을 하는것은 아닌거 같다.(필자의 테스트결과)
하지만 key가 겹치게된다면 매우 높은 확률로 재 렌더링을 한다는 것이다.
※아 그리고 key가 없으면 인덱스를 그냥 key로 넣는다는 주장이 있다. 주장인데 신빙성은 있는 듯.
이는 몇가지 테스트를 통하여 확인하였다.

테스트 조건은 아래와 같다.
데이터 앞에 신 데이터 끼워넣기
1. 크기와 색, 위치는 렌덤인 div에 숫자를 넣는다. 갯수는 1만개이다.
2. 3초후에 1만개의 div를 추가적으로 기존 데이터의 앞에 추가한다.(즉 배열은 2만개가 되고 앞의 1만개는 신데이터, 과거 1만개는 구데이터)
3. 그 후 과거 1만개가 생성된 직후에서 새로 1만개가 생성된 직후의 시간차이를 계산한다.
4. 3개의 대조군을 만드는데 하나는 key가 없는 녀석, 하나는 key가 있지만 중복이 발생하는 녀석, 하나는 key가 있고 유니크한 녀석이다.
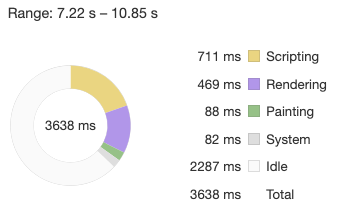
이렇개 개발자 도구 켜서 총 걸리는 시간을 확인하겠다는 뜻이다.
그럼 실험 결과를 공개하겠다. 단위는 초이다.
key가 없는 경우 => 3.92 3.81 3.92 3.94 4.10
key가 있지만 유니크하지 않음 => 3.68 3.77 3.63 3.66 3.72
key가 있고 유니크함 => 3.55 3.47 3.58 3.58 3.36
평균을 내보면
key(없음) = 3.93
key(중복) = 3.69
key(유니크) = 3.5
키가 없는것 보다는 중복되더라도 있는게 빨랐고 중복된것보단 유니크한게 빨랐다.
하지만 여기서 함정이 있는데 위의 경우에는 데이터의 순서가 유지가 됬기 때문에 중복이 되어도 재 렌더링이 거의(혹은 전혀)일어나지 않는다.
아마 vue에서 과거데이터와의 대조를 통하여 key가 없어도 어느정도 캐싱효과를 보장해주는것 같다.
일반적인 경우에는 중복된다면 없는게 더 나은데 그 이유는 아래를 보면 알 수 있다.
실험 방식을 약간 바꿔보자.
과거 데이터와 신 데이터를 교차로 섞기
1. 크기와 색, 위치는 렌덤인 div에 숫자를 넣는다. 갯수는 1만개이다.
2. 3초후에 1만개의 div를 추가적으로 기존 데이터와 셔플하듯이 사이에 교차로 추가한다.(즉 배열은 2만개가 되고 앞의 1만개는 신데이터, 과거 1만개는 구데이터)
3. 그 후 과거 1만개가 생성된 직후에서 새로 1만개가 생성된 직후의 시간차이를 계산한다.
4. 3개의 대조군을 만드는데 하나는 key가 없는 녀석, 하나는 key가 있지만 중복이 발생하는 녀석, 하나는 key가 있고 유니크한 녀석이다.
이 경우 어떻게 될까?
놀랍게도 결과는 이상하게 전개된다.
key가 없는 경우 => 3.99 4.00 3.88 4.01 4.04
key가 있지만 유니크하지 않음 => 5.7 5.53 5.10 5.23 5.29
key가 있고 유니크함 => 3.60 3.58 3.63 3.56 3.63
평균을 내보면
key(없음) = 3.98
key(중복) = 5.37
key(유니크) = 3.6
오히려 키가 중복될 때 성능이 눈에 띄게 하락하는 것을 확인할 수 있다.
그 이유는 제랜더링이 눈에 띄게 많이 일어나는데 이는 아래의 그림을 보면 알 수 있다.
사진속 마우스 커서가 새로 고침을 누른 시점에서 확인하라!
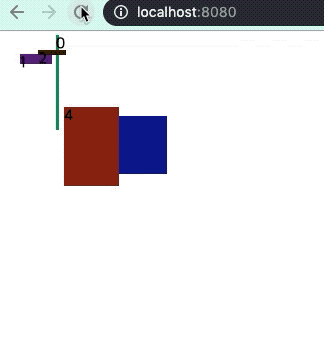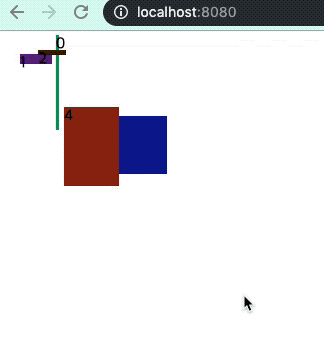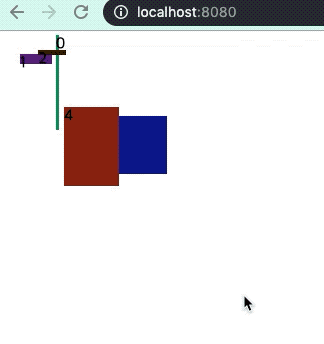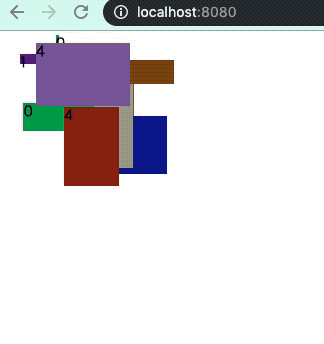
key가 없는 경우이다.

key가 있고 중복되지 않는 경우이다.

key가 있는데 중복되는 경우이다.
뭔가 차이가 느껴지는가?
위의 둘은 기존 컴포넌트(돔)이 사라지지 않고 추가만 됬지만 key중복이 있는 경우 몇개는 없어지고 재 렌더링이 된다.
일종의 캐싱 효과를 못 받는걸로 해석된다.
애당초 key가 중복된다는 것은 일종의 버그이다. "특정 상황에서 key가 있을 때 없을 때"의 성능이 다르긴하지만
그걸 논하는건 무의미하며 정의된 스펙이 아니다. 따라서 그냥 key는 유니크하게 만들어야한다.
결론
1. key는 성능에 영향을 확실하게 미친다.
2. key가 없는 경우 데이터가 삽입 정도와 정렬정도에 따라서 캐싱효과를 보고 못보고가 결정된다.
3. key가 중복되는데 캐싱을 못볼경우 그냥 재 렌더링 해버리는데 그 사이드 이펙트가 클 수도 있다.
4. key를 쓸꺼면 아예 중복안되게 key를 만들고 안 쓸거면 그냥 쓰지 않는게 낫다.
결론 중의 결론
무조건 유니크한 key를 쓰자
'Develop > Front-End' 카테고리의 다른 글
| 웹페이지는 어떻게 로딩이 되는가 (0) | 2022.02.24 |
|---|---|
| 웹페이지가 로딩되는 순서 보기(2) (0) | 2022.02.24 |
| [Cookies] 웹 쿠키제어(get, set, remove) (0) | 2021.02.19 |
| Chrome( 크롬) 브라우저에서 로그(Log) 유지 (0) | 2020.12.16 |
| [vue.js] firebase 배포 (0) | 2020.12.14 |


